


At Corti, we’re actively working on new ideas for automated medical coding.
Automated medical coding models predict medical codes from clinical notes. These codes are alphanumeric representations of diagnoses or procedures used for documentation, billing, and statistics.
Progress in automated medical coding has stagnated. There has been virtually no innovation since the introduction of label-wise attention in 2018 — only variations of the same ideas. It is time for something new.
This is a bold claim, but we believe our new framework, Code Like Humans (CLH), is what the field desperately needs. Our paper presenting the framework was recently accepted for EMNLP 2025 findings. In this post, we will cover how it works and what comes next. However, to motivate our framework, we will first explain why existing approaches fail and how professional medical coders assign codes.
Why current approaches fail
Current state-of-the-art medical coding models require large datasets of clinical notes annotated with medical codes. In effect, these models memorize codes present in the training data. This approach has several limitations:
Acquiring clinical notes annotated with medical codes is challenging. Most health care providers are unable or unwilling to share such valuable private data.
A code must appear frequently for models to predict it reliably. Thus, models are unable to predict codes that do not occur in the training data and struggle with rare codes. In MIMIC-IV, only 6,000 out of the 70,000 ICD-10-CM codes appear in the training data.
Coding systems, such as ICD-10-CM and CPT, are updated annually. Adapting the models to predict the new versions requires re-annotating the datasets and re-training the models.
Models trained on codes from one department or specialty may not generalize well to another.
Several studies address these challenges by training models to use external resources describing the codes rather than memorizing them. External resources include the code hierarchies, code descriptions, code synonyms, and code co-occurrences. Although using external resources is a logical solution to the problem, previous studies on ICD coding have misused the resources and neglected essential resources such as the alphabetic index and the official guidelines (see this blog post for a more detailed criticism of these approaches).
Recent studies also explore large language models (without fine-tuning) for code extraction, data augmentation for rare codes, and few-shot learning. Most show poor results, except for those that deviously evaluate on artificially generated data, despite real-world data being publicly available.
The greatest weakness of current approaches is that they overlook how humans assign medical codes. Here is how humans do it.
How humans assign medical codes
Many coding systems are used in healthcare, but we will focus on ICD-10: the International Classification of Diseases, 10th Revision, which is the primary coding system used for documenting diagnoses in most countries worldwide.
Understanding ICD-10 Code Structure
ICD-10 codes follow an alphanumeric format that reflects a hierarchy. Each code begins with a letter (A-Z) followed by two digits, creating three-character categories (e.g., J44: Other chronic obstructive pulmonary disease). Codes can be extended with a decimal point and additional characters, up to two in the international version and up to four in the American modification, ICD-10-CM.
The hierarchy is structured as follows:
ICD Chapters: The initial letter groups codes into 22 broad chapters covering different body systems or types of conditions (e.g., Chapter 10, "Diseases of the respiratory system," uses codes J00-J99)
Categories: Three characters representing general condition types within each chapter (e.g., J44: Chronic obstructive pulmonary disease)
Subcategories: Four characters (four to six in ICD-10-CM) providing additional information (e.g., J44.0 = COPD with acute lower respiratory infection)
Codes: Leaf nodes in the ICD hierarchy. Can have between three and five characters (or up to seven in ICD-10-CM). A category is a code if it has no child nodes.
With approximately 14,000 codes in the international ICD-10 (and about 70,000 in the American ICD-10-CM modification), navigating this vast classification system requires systematic tools and resources.
The Three Essential Coding Resources
For ICD coding, human medical coders rely on three resources to navigate this extensive hierarchy:
The tabular list contains the hierarchy. It further contains instructional notes that specify when to exclude or add supplementary codes. For example, at code I50.9 (Heart failure, unspecified), the tabular list includes the instruction "code first," directing coders to also assign a code for the underlying condition that caused the heart failure, such as hypertension.
The alphabetic index serves as the entry point into the hierarchy, with an extensive cross-reference of medical terms, conditions, and synonyms that direct coders to the appropriate categories, subcategories, or codes in the tabular list. Rather than searching through thousands of codes sequentially, coders can quickly jump to the relevant part of the hierarchy.
The guidelines provide rules for code selection within the hierarchy. The guidelines include general coding principles that apply across all chapters, plus chapter-specific instructions that address unique coding considerations for different body systems and condition types.
The Coding Process
Medical coding is translation, converting the messy language of clinical practice into ICD-10's rigid hierarchy. The process mirrors how we naturally move from general to specific, uncertainty to precision.
Step 1: Extract signal from noise
The medical record contains everything. First, one must extract what matters for coding. Identify the conditions that influenced care delivered in the current admission. Everything else is noise.
Step 2: Navigate the alphabetic index
For each identified condition, look up the main term (usually the condition's noun) in the alphabetic index. Each main term has modifier terms, which you must use to specify the condition further. The final term points one to a code or sub-category. The alphabetic index suggests codes but gives no final answers. It's like a search engine.
Step 3: Verify each code in the tabular list
Use the tabular list to verify the code suggested by the alphabetic index or to traverse down the hierarchy when a sub-category is suggested. As mentioned, the tabular list also provides instructional notes that offer more information for selecting the appropriate codes and when to add or exclude codes.
Step 4: Verify the final list
While the two previous steps have focused on each condition separately, this step considers the entire list of code candidates identified so far. Using the instructional notes and guidelines, remove codes that should not be reported together. For example, mutually exclusive ones or a symptom code when a definitive diagnosis is coded. Then sequence the codes.
Code like humans
The idea behind Code Like Humans is simple. We designed four agents following the steps above, as shown in the figure:
Evidence extractor. Identifies codeable conditions in clinical notes.
Index navigator. Iterating through each codeable condition, the agent locates the term in the alphabetical index. The output is a list of candidate codes.
Tabular validator. Verifies and refines the candidate codes from the Index navigator by using the tabular list and chapter-specific guidelines.
Code reconciler. Considers all the code candidates identified by the Tabular validator. Using the guidelines and instructional notes, it removes codes and sequences the final list.
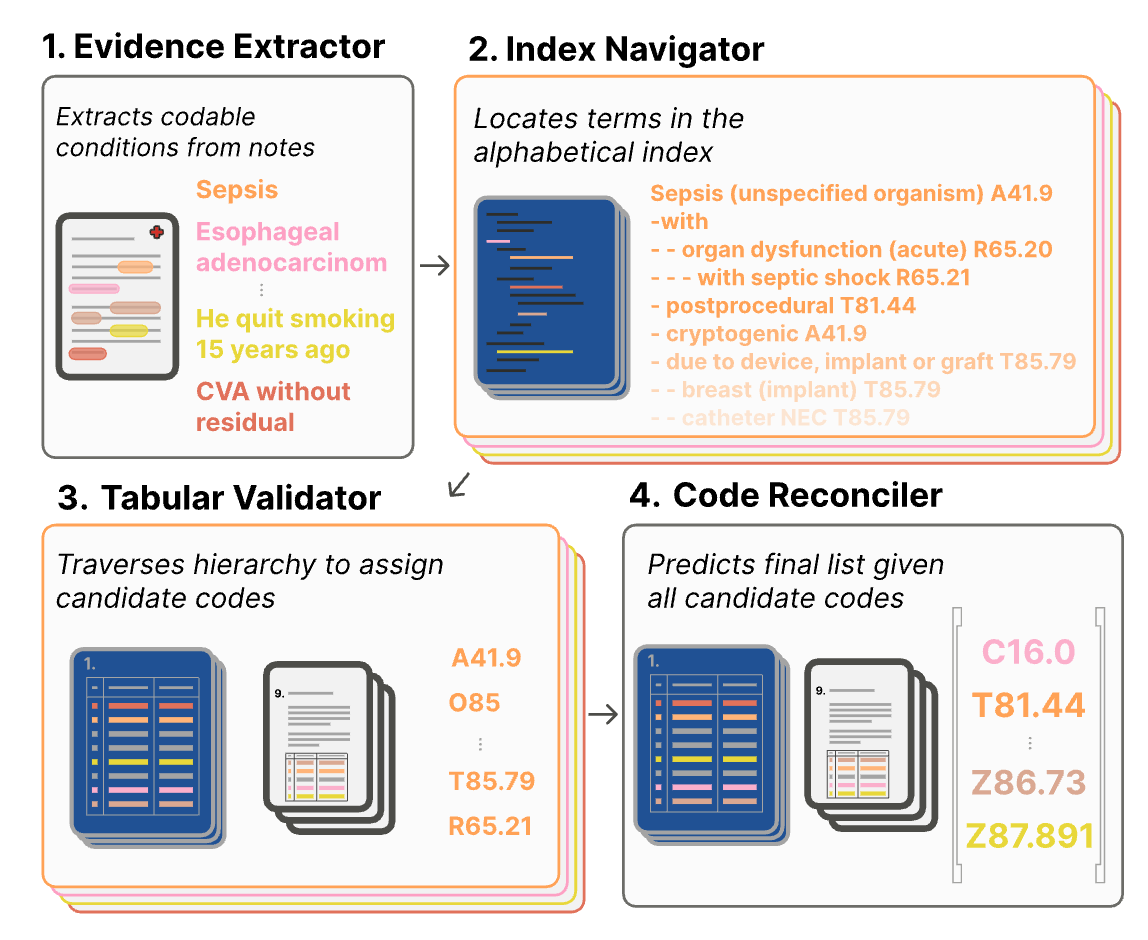
Our implementation was primitive; it was intended as a proof-of-concept. Our agents were large language models without any fine-tuning. The agents don’t need to be large language models. For instance, the index navigator can be a search engine.
Results
We compared Code Like Humans with PLM-ICD, a state-of-the-art model trained on clinical notes annotated with ICD-10 codes (MIMIC-IV). We evaluated the methods on MDACE, which consists of 300 clinical notes from MIMIC reannotated by professional medical coders.
Despite not being fine-tuned for the task, Code Like Humans achieved a higher F1 macro score than PLM-ICD (28% vs 25%). However, PLM-ICD achieved a superior F1 micro score (48% vs 43%). These results suggest that Code Like Humans is better at predicting rare codes, while PLM-ICD is better at predicting frequent codes. So which is better?
We trained and evaluated PLM-ICD on data from the same department. As a result, the codes that were frequent in the training data were also frequent in the test data. This gave PLM-ICD an unfair advantage. If we had tested on a different department in a different specialty, other codes would have been frequent, which would remove PLM-ICD’s advantage.
On the other hand, PLM-ICD is only trained on discharge summaries, while we evaluated the methods on all clinical note types. This was a disadvantage for PLM-ICD; however, it is something it ideally should be capable of handling.
Next steps
Whether this version of Code Like Humans is superior to PLM-ICD is inconsequential; what matters is its potential. PLM-ICD trained on MIMIC can only predict the 6,000 codes that appear in the training set; Code Like Humans can predict all 70,000 ICD-10-CM codes. PLM-ICD must be retrained to support a new ICD-10 version; Code Like Humans simply needs access to the latest guidelines, tabular list, and alphabetic index. PLM-ICD sucks at predicting rare codes; our basic implementation of Code Like Humans sucks less.
There are many low-hanging fruit for the proceeding studies. Each agent can be evaluated independently:
Evidence extractor: Compare the output with human-annotated evidence spans from MDACE or Douglas et al. (2025).
Index navigator: Compare the output with ground-truth terms. One can find the ground-truth terms by back-tracing from the annotated ICD-10 codes. To control the input of the agent, provide it with ground truth evidence that spans from MDACE.
Tabular validator: Provide the agent with a set of candidate codes/sub-categories, where the human-annotated code from MDACE is among them.
Code reconciler: Provide the agent with a list of codes where some of them are incorrect. Measure how well the model performs in removing incorrect codes from the list. You can also measure how well the agent orders the list. We did not do the latter in the paper.
Since each agent can be evaluated individually, one study can focus on improving one agent. The field can work in parallel on different agents, and by combining the improved agents, we may collectively achieve a new state-of-the-art method. If you are interested in joining this effort, check out the error analysis of each agent in the paper. We show, for instance, that the evidence extractor struggles in identifying codeable terms that are not related to diseases, such as smoking habits and instructions about resuscitation.
 | A guest post by
|