
An Unsupervised Approach to Achieve Supervised-Level Explainability in Healthcare Records
A deep dive into our EMNLP 2024 paper

Our paper, "An Unsupervised Approach to Achieve Supervised-Level Explainability in Healthcare Records," was recently accepted to the main conference of EMNLP 2024.
This blog post will explore the paper's core ideas and findings. Specifically, we'll examine how we developed a new method for generating explanations for automated medical coding models that rival supervised approaches' performance—without requiring expensive annotations.
The Power of Explanations
Explainability is crucial for making automated medical coding useful in the real world. Consider the following example:

Validating these codes is time-consuming, even for this relatively simple example. You must locate the evidence of each medical code and then verify if that evidence is sufficient. Imagine when the clinical note comprises thousands of words!
Now, look how much easier it becomes with explanations:
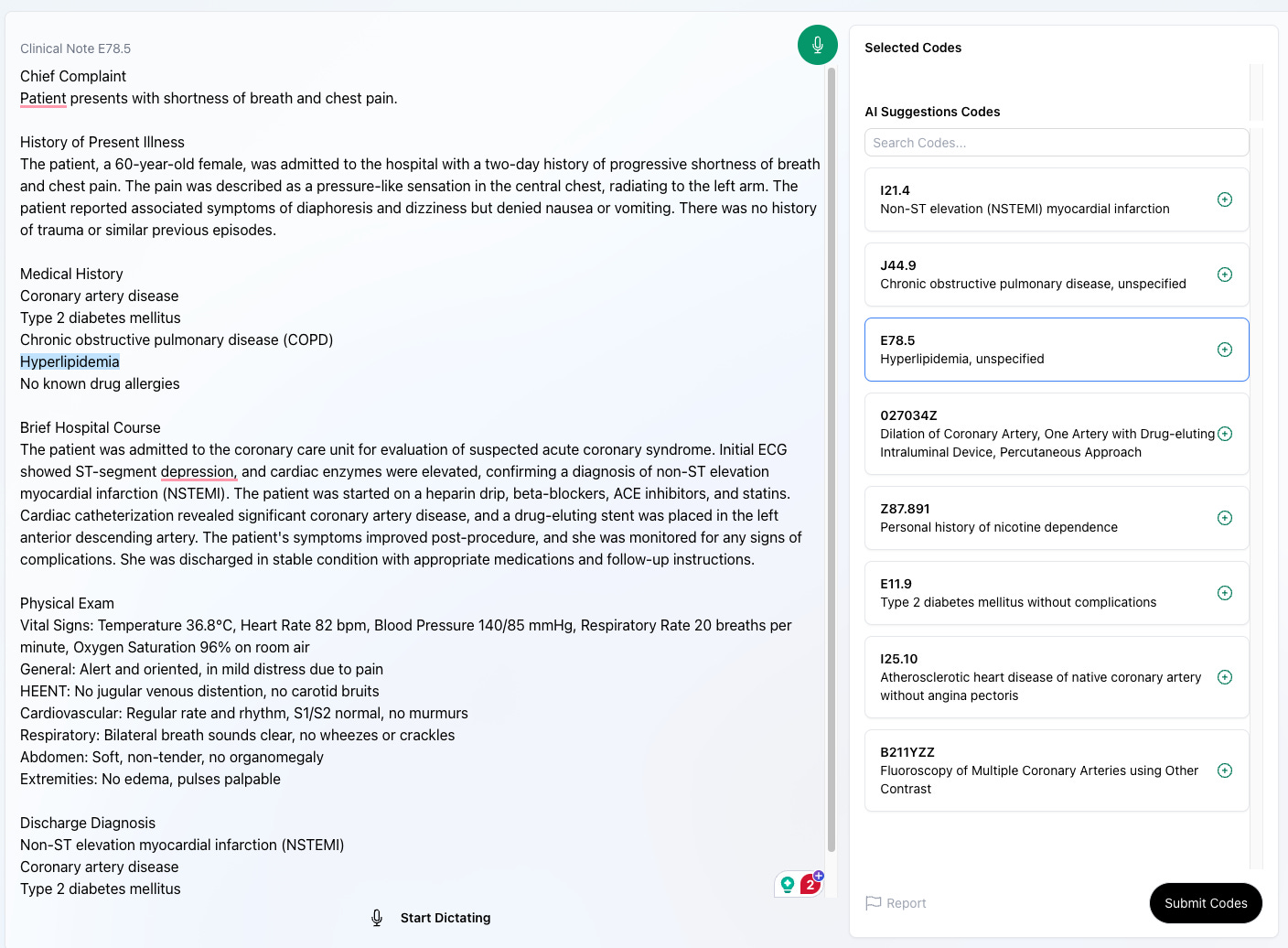
You can hover your mouse over the code, and it will show you the evidence—much faster! Not only can it help us validate errors faster, but it can also be an excellent tool for debugging the model.
Unexpected Model Behavior
For example, in one case, our model predicted the code Z72.51: High-risk heterosexual behavior for a patient involved in a motorcycle accident. This was surprising because Z72.51 represents irresponsible sexual behavior, and there was no mention of sexual activity in the text. The explanation showed that the model predicted the code because the patient rode a motorcycle. The model had learned some incorrect correlation between motorcyclists and irresponsible sex!

Explanations are obviously helpful; however, producing high-quality explanations is a challenging, unsolved problem.
The State of Explainable Medical Coding
Multiple studies propose explanation methods for automated medical coding models. Most of them use the attention weights from the final layer as the explanation. A study from 3M provides the state-of-the-art explanation method. They hired medical coders to annotate medical codes and the relevant evidence in the clinical notes. When training their automated medical coding model, they also trained the attention weights to focus on the annotated evidence spans, improving the attention weights’ explainability.
However, evidence-span annotations are expensive. We once were offered to buy a dataset comprising 12,000 examples annotated with medical codes and evidence spans. It cost $420,000. We would need such a dataset for each code system and language—not scalable!
Our Approach: Explanations Without Expensive Annotations
The beauty of medical coding is that almost every medical document in the world is annotated with medical codes because they are required for statistics and billing. Consequently, most hospitals have datasets that can be used to train automated medical coding models. Therefore, we asked the question: Can we produce high-quality explanations only using medical documents and codes, i.e., no evidence-span annotations?
Spoiler alert—yes, we can. In our EMNLP paper, we demonstrated that we could produce explanations of similar quality as 3M but without using evidence span annotations. We achieved this feat with two contributions:
We improved the explanation method.
We improved the model's robustness.
Let's dive into the details!
Model Architecture: PLM-CA
To understand our experiments, it's helpful to know the model architecture we used. We employed a variant of PLM-ICD, which we named PLM-CA. Here's a simplified overview of its architecture:
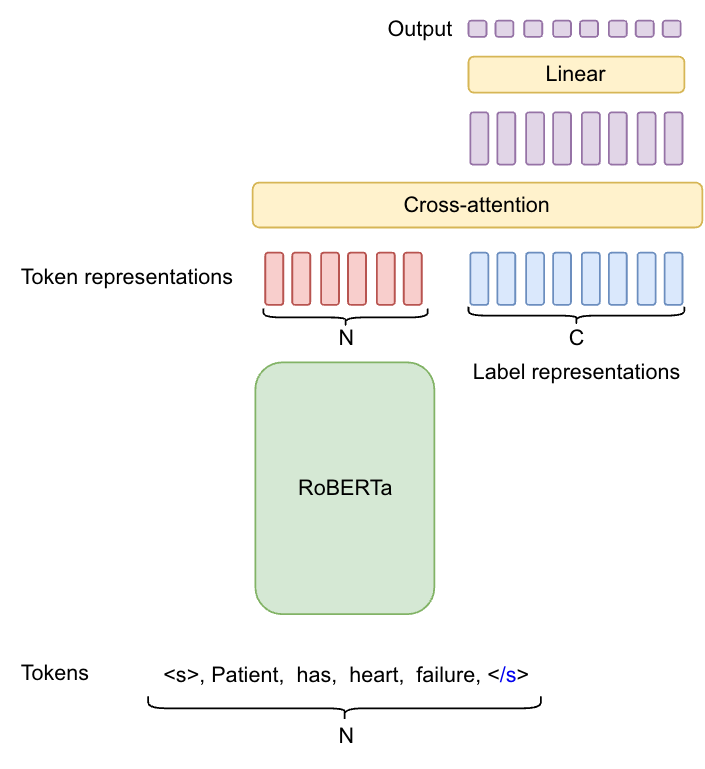
Components:
Input: Clinical text (e.g., "Patient has heart failure") and potential medical codes
RoBERTa Encoder: Transforms words into rich vector representations
Cross-attention: Compares medical codes with word meanings
Output: Probability scores for each medical code
How It Works:
Text Encoding: The clinical text is fed into RoBERTa, which encodes each word (token) into a vector that captures its meaning and context.
Label Representation: Each potential medical code (label) also gets its own vector representation.
Cross-attention Magic: This is where the real matching happens. The cross-attention layer compares each medical code with every word in the text.
Final Prediction: A linear layer takes each updated code representation and calculates a probability score.
Now that we understand the model architecture let's move on to how we improved the explanations.
Improved Explanation Method: AttInGrad
We aimed to improve the explanation method. Since previous studies only evaluated attention-based explanation methods, we tested other approaches, such as gradient-based and perturbation-based methods. Surprisingly, these methods produced worse explanations than attention.
We noticed that the errors from attention-based and gradient-based methods rarely overlapped. By multiplying the feature attribution scores, we created a new method called AttInGrad, which significantly improved the explanations.
So, how much better is it, exactly? We evaluated plausibility, which is how convincing the explanations are for humans. We estimated plausibility by comparing the predicted important words with the annotated evidence spans. These are the F1 scores:
InputXGrad (gradient-based method): 31.6%
Attention: 36.5%
AttInGrad: 41.5%
Quite an improvement! AttInGrad also improved the faithfulness of the explanations, i.e., it more accurately reflected the model’s inner workings.
I will explain why AttInGrad improved the results later.
Enhancing Model Robustness
An explanation can be entirely faithful—accurately reflecting the model's internal mechanisms—yet still be difficult or impossible for humans to understand. If the model's underlying processes are flawed, a faithful explanation of those processes will inherit those flaws, making it challenging to understand or interpret correctly. For instance, if our model thinks that a person has irresponsible sex because he rides a motorcycle, our explanation will look weird, no matter how accurate it is.
Adversarial examples reveal flaws in a model’s inner mechanisms. Basically, you can add invisible noise to the input that tricks machine-learning models. For example, you can fool an image classifier into thinking an image of a cow is an image of an airplane. There is a paper called "Adversarial Examples Are Not Bugs, They Are Features" which shows that image classifiers learn to use tiny pixel changes as features. Consequently, faithful explanations for such sensitive models look weird, and they should! If a tiny change to a pixel changes the output, the explanation should highlight it as important. The issue isn't the explanation method; it is the model!
Several papers show that we can make explanations more plausible by training the models to be robust against adversarial examples. The results from the paper Robustness May Be at Odds with Accuracy by Tsipras et al. are particularly striking. The top row shows the image, the second row shows the explanation from a standard model, and the last two rows show explanations produced by two different adversarially robust models. They all use the same explanation method, yet the difference is striking.

We evaluated whether improving our medical coding model's robustness towards adversarial examples also improved the plausibility of explanations. This has been demonstrated in image classification studies but not in text classification.
We tested three adversarial training approaches and found that token masking was most effective. Token masking identifies the least important tokens during training and replaces them with a <mask> token, teaching the model not to rely on irrelevant tokens.
Token masking improved the plausibility of most explanation methods:
InputXGrad (gradient-based method): 31.6% → 33.1%
Attention: 36.5% → 37.0%
AttInGrad: 41.5% → 41.9%
In my previous blog post, I explain the relationship between the model and the explanation method in more depth.
Combining the Improvements
By combining our improved explanation method (AttInGrad) with the enhanced model robustness (using token masking), we produced explanations with plausibility similar to that of the supervised state-of-the-art method but without requiring expensive annotations.
Here's how our approach compares to other methods:

As you can see, our unsupervised method (AttInGrad+TM) performs comparably to the supervised state-of-the-art method from 3M (Attention+Bs), while significantly outperforming previous unsupervised approaches (Attention+Bu).
Unmasking the Mystery: Why AttInGrad Outperforms Attention
While both AttInGrad and Attention produced better explanations than other methods, they showed a much higher variance in their results across different runs of the model training. This means that training the same model multiple times with different random starting points could lead to very different explanations, even if the model's accuracy remained consistent.
Upon closer examination, we discovered that Attention often highlighted "special tokens" as highly important for its predictions. These special tokens include things like punctuation marks, spaces, and artifacts from the text encoding process. These tokens don't carry significant meaning for humans trying to understand the reasoning behind a medical code assignment. In fact, we showed that special tokens accounted for only 5.8% of the tokens within the human-annotated evidence spans.
This reliance on special tokens by Attention explains the high inter-seed variance. The figure below shows the relationship between the proportion of special tokens among the top five most important tokens and the F1 score (representing plausibility). Each point on the plot represents the average statistic for a single run of the model training.

For both Attention and AttInGrad, there is a strong negative correlation between the proportion of special tokens and both F1 score and Comprehensiveness. This means that as the explanations rely more heavily on special tokens, their quality decreases.
InputXGrad, in contrast to Attention, demonstrates much lower variance across runs and focuses more consistently on meaningful words. By incorporating InputXGrad, AttInGrad benefits from this more stable behavior and reduces the influence of these misleading special tokens. AttInGrad is essentially using InputXGrad to reduce its reliance on special tokens, thereby improving its performance.
Findings after the paper submission
It’s been 3.5 months since we submitted the paper. Since then, we have learned a lot. Here are our main realizations:
Gradient-based methods are terrible. I cover this in this blog post.
Cross-attention (also called label-wise attention) was key to the good performance of Attention and AttInGrad. We later found that these methods produced poor explanations for architectures with multi-head attention and skip connections in the final layer. I will discuss this in a later blog post.
DecompX achieved impressive results in our recent paper on the sentiment classification class. I evaluated it for automated medical coding and found it to perform similarly to Attention.
Conclusion
Our research demonstrates that it's possible to produce high-quality explanations for automated medical coding without relying on expensive annotated datasets. By improving both the explanation method and the model's robustness, we've taken a significant step toward making automated medical coding more transparent and trustworthy.
I will present the paper at EMNLP 2024 in Miami; I hope to see you there!